
Building a Database with Amazon Aurora
Used parallel query from Amazon Aurora to the U.S. flight data records to optimize the performance of analytical workloads.
CLOUD PROJECTS
2/1/20244 min read


Purpose: Perform parallel queries when necessary. Parallel queries are beneficial for analytical workloads requiring high performance on large tables. Amazon Aurora has the feature of delegating I/O to the storage nodes.
Used AWS services: Amazon Aurora, VPC, EC2, Amazon CloudWatch
One of Amazon Aurora's great benefits is that it is compatible with MySQL and PostgreSQL and helps with time-consuming things like hardware provisioning, patching, and backups. A feature that Amazon Aurora has is the ability to do parallel queries in specific situations when handling large datasets.
The project involves using the United States flight records to see how they benefit from the features of the parallel query. One of the great things about it is that it does not lean on the CPU capacity of the database server.
Starting the project:
I connected to the Aurora instance by running some commands to check the flight data. That data contains the table for the on-time flights with information about carriers and flight data.
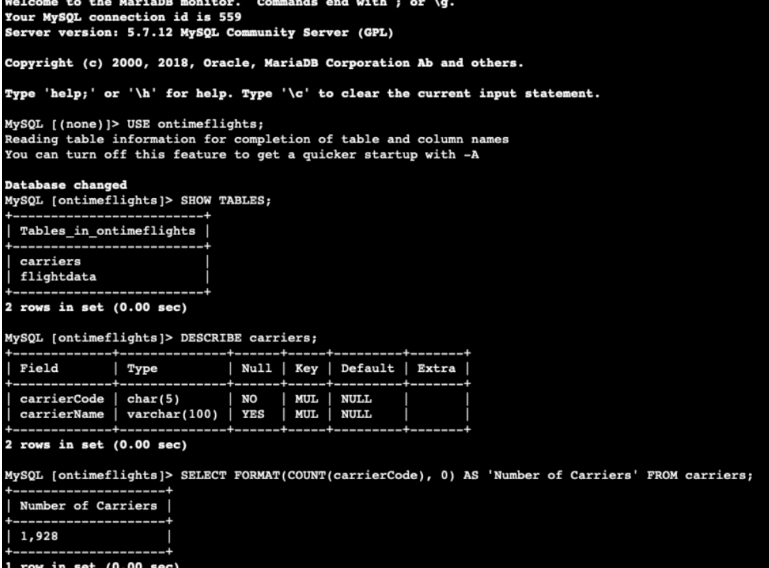
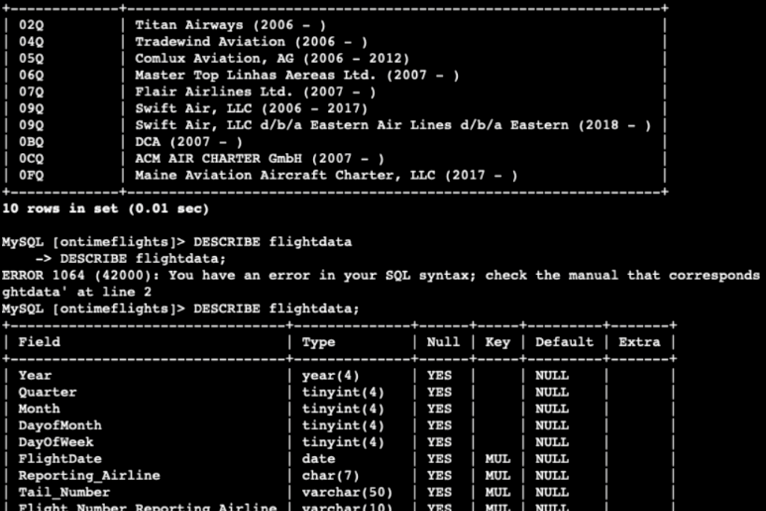
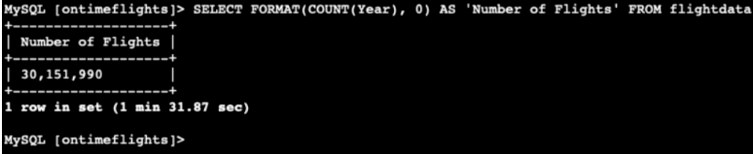
I filtered only ten carriers to see their flight data. I noticed that there are more than 30 million rows. That is a lot of data! This is a case when a parallel query with Amazon Aurora is beneficial. We have a lot of data to analyze, so this can be an ideal solution.
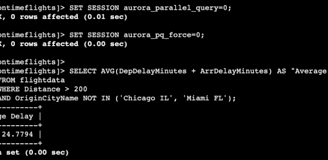
I ran the command statements to check if the database instances were enabled for the query. It's good to know that you can enable and disable it. So here are examples of the commands.

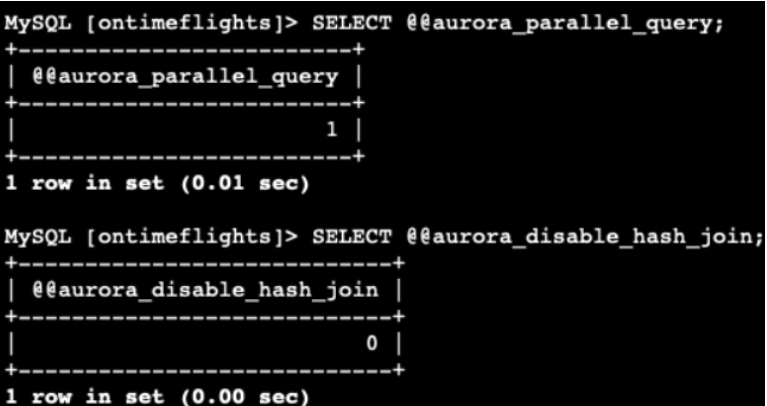
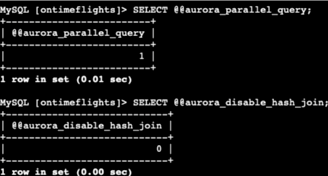
Amazon Aurora determines which statements to use. We can add SET SESSION to enable it without modifying the global settings, or if we want, we can force it to do so as well.
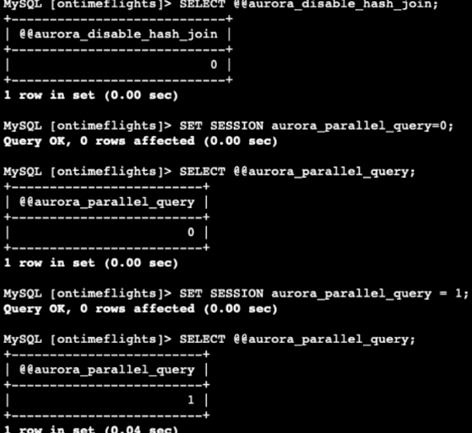
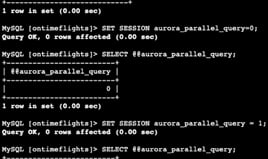
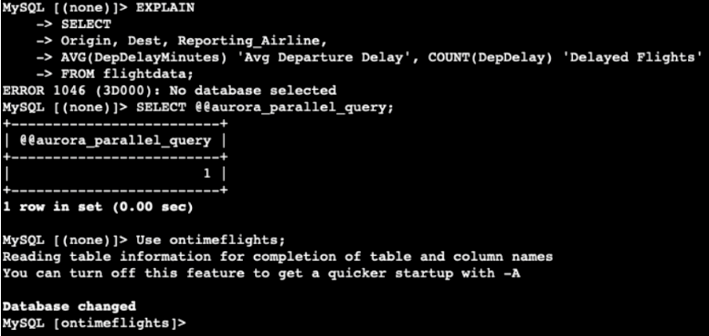
I encountered a small error because the databases logged me off, and when I ran the EXPLAIN statement, it said that the database was not selected. I had to select it one more time.
Moreover, the EXPLAIN statement helped me to know which statements can be ideal for parallel queries.
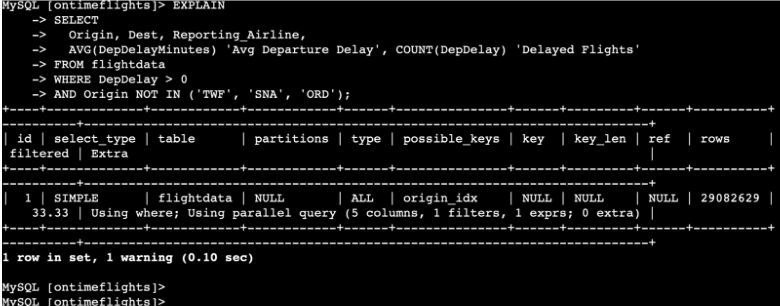
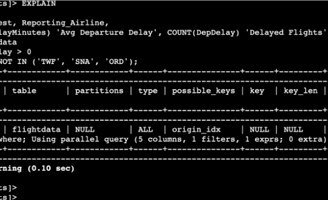
Many read requests
Running without the parallel query disabled will cause the database instance to be used instead of the storage layer.
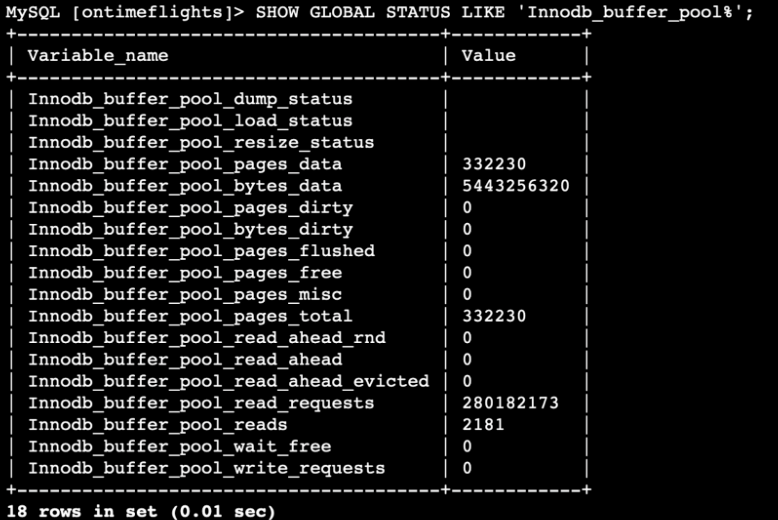
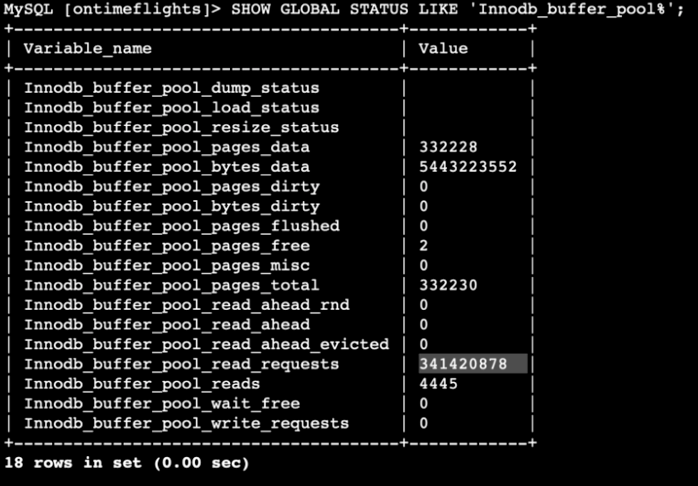
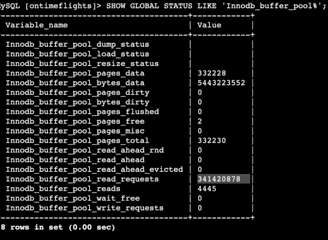
Math for the Innodb_buffer_pool_read_requests is 280182173 - 310797595 = 30,615,422. When the parallel query was disabled.
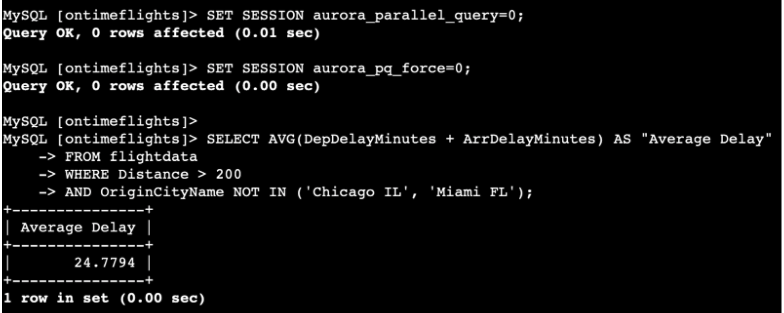
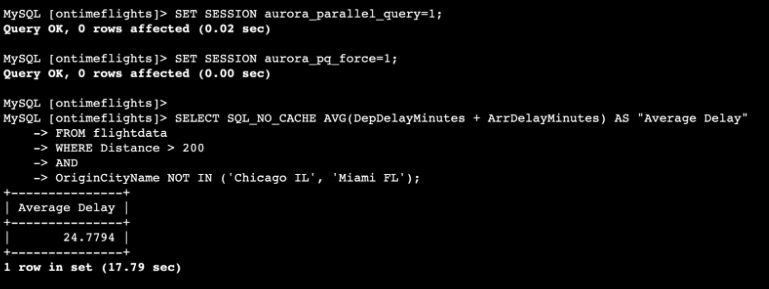
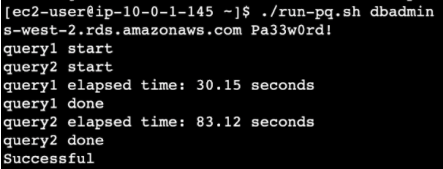
Running without a query or cache causes it to be slower in returning results, lasting from a second to a few minutes.
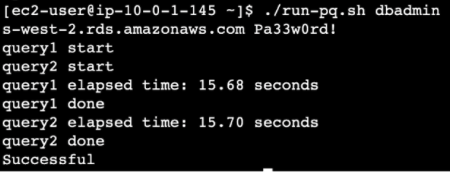
Running it cached causes it to be much faster in two seconds.
Running it with a parallel query takes about 20 seconds but is more reliable.
Running it without parallel query or cached takes about 1 minute 40 seconds.
341416017 - 341420878 = 4,861.When the parallel query is enabled, it decreases the buffer pool read request, which is amazing to use! It is a significant difference.
Also, the maximum parallel query that the large instance can run is eight, and for the small instance, it is one.
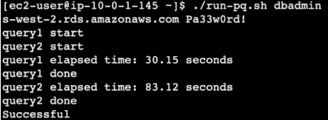
Large instance:
Small instance:
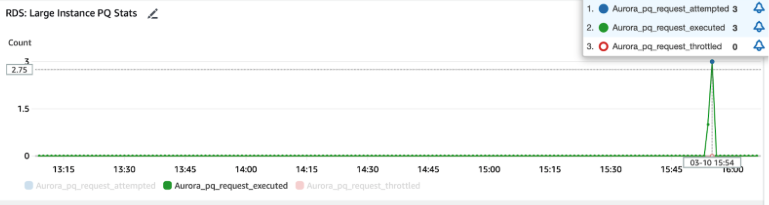
This large instance can support up to 8 concurrent parallel query requests. During the period in question, there were two active queries, each utilizing two parallel sessions, totaling four sessions in use. Given the instance's capability to handle eight parallel sessions simultaneously, the workload was well within its limits. Thus, there was no throttling, meaning no parallel query requests were denied or limited due to resource constraints, ensuring smooth and efficient database operations.
Conclusion:
Using parallel queries on large datasets is ideal and highly beneficial because it significantly enhances query performance and reduces the time it takes to process vast data. This approach allows faster data retrieval and processing, enabling more efficient analysis and decision-making. Furthermore, it optimizes resource utilization, ensuring that large datasets can be managed and analyzed more effectively. Parallel querying, thus, is a vital tool in handling complex queries and large datasets, making it an indispensable feature for businesses and applications that require quick access to insights from big data.
Metrics from CloudWatch for the large instance: